DataHut
A small, portable data warehouse for Ruby for analytics on anything!
DataHut has basic features for small one-off analytics like parsing error logs and such. Like its bigger cousin (the Data Warehouse) it has support for extract, transform and load processes (ETL). Unlike its bigger cousin it is simple to setup and use for simple projects.
Extract your data from anywhere, transform it however you like and analyze it for insights!
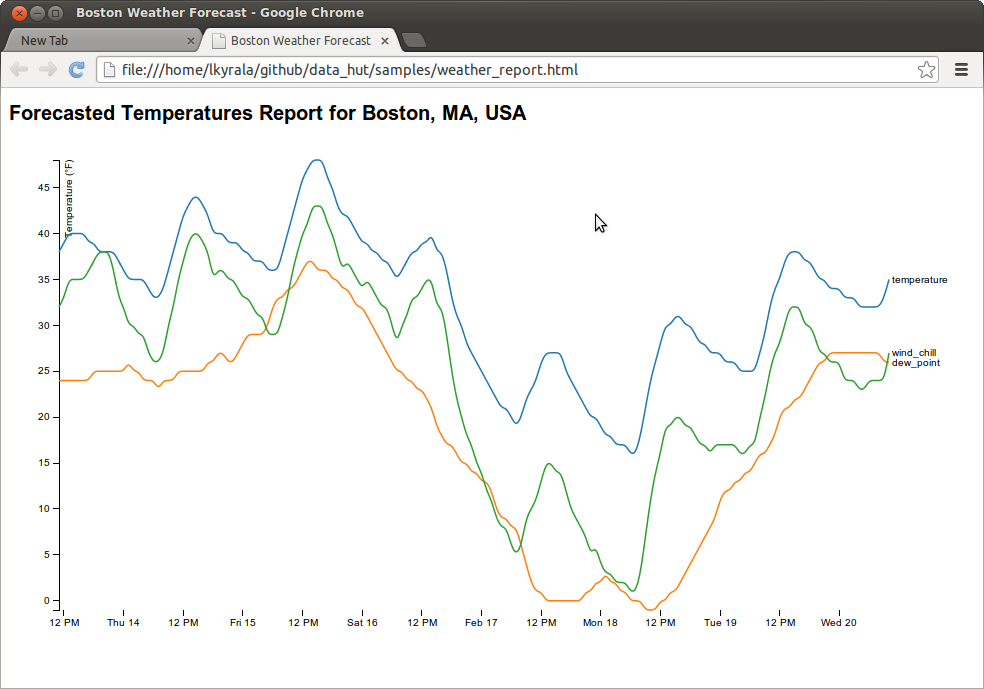
from samples/weather_station.rb
Installation
Add this line to your application's Gemfile:
gem 'data_hut'
And then execute:
$ bundle
Or install it yourself as:
$ gem install data_hut
Usage
Setting up a datahut is easy...
require 'data_hut'
require 'pry'
dh = DataHut.connect("scratch")
data = [{name: "barney", age: 27},
{name: "phil", age: 31},
{name: "fred", age: 44}]
# extract your data by iterating over your data format (from whatever source) and map it to a record model...
dh.extract(data) do |r, d|
r.name = d[:name]
r.age = d[:age]
end
# transform your data by adding fields to it
dh.transform do |r|
r.eligible = r.age < 30
end
# operate on your dataset by using chained queries
ds = dh.dataset
binding.pry
DataHut provides access to the underlying Sequel::Dataset using a Sequel::Model binding. This allows you to query individual fields and stats from the dataset, but also returns rows as objects that are accessed with the same uniform object syntax you used for extracting and transforming... i.e.:
[1] pry(main)> person = ds.first
[2] pry(main)> [person.name, person.age]
=> ["barney", 27]
And here's some of the other powerful things you can do with a Sequel::Dataset:
[2] pry(main)> ds.where(eligible: false).count
=> 2
[3] pry(main)> ds.avg(:age)
=> 34.0
[4] pry(main)> ds.max(:age)
=> 44
[5] pry(main)> ds.min(:age)
=> 27
But you can also name subsets of data and work with those instead:
[6] pry(main)> ineligible = ds.where(eligible: false)
=> #<Sequel::SQLite::Dataset: "SELECT * FROM `data_warehouse` WHERE (`eligible` = 'f')">
[26] pry(main)> ineligible.avg(:age)
=> 37.5
[24] pry(main)> ineligible.order(Sequel.desc(:age)).all
=> [#< @values={:dw_id=>3, :name=>"fred", :age=>44, :eligible=>false}>,
#< @values={:dw_id=>2, :name=>"phil", :age=>31, :eligible=>false}>]
And results remain Sequel::Model objects, so you can access fields with object notation:
[32] pry(main)> record = ineligible.order(Sequel.desc(:age)).first
=> #< @values={:dw_id=>3, :name=>"fred", :age=>44, :eligible=>false}>
[33] pry(main)> record.name
=> "fred"
[34] pry(main)> record.age
=> 44
Or you can output results directly to JSON.
[1] pry(main)> puts ds.group_and_count(:name).all.to_json
[{"name":"barney","count":3},{"name":"fred","count":1},{"name":"phil","count":2}]
(See samples/weather_station.rb for an example of using JSON output to visualize data with d3.js.)
Read more about the Sequel gem to determine what operations you can perform on a DataHut dataset.
A More Ambitious Example...
Taking a popular game like League of Legends and hand-rolling some simple analysis of the champions. Look at the following sample code:
Running this sample scrapes some game statistics from an official website and then transforms this base data with extra fields containing different totals and indices that we can construct however we like. Now that we have some data extracted and some initial transforms defined, lets play with the results...
who has the most base damage?
[1] pry(main)> ds.order(Sequel.desc(:damage)).limit(5).collect{|c| {c.name => c.damage}} => [{"Taric"=>58.0}, {"Maokai"=>58.0}, {"Warwick"=>56.76}, {"Singed"=>56.65}, {"Poppy"=>56.3}]but wait a minute... what about at level 18? Fortunately, we've transformed our data to add some extra "total" fields for each stat...
[2] pry(main)> ds.order(Sequel.desc(:total_damage)).limit(5).collect{|c| {c.name => c.total_damage}} => [{"Skarner"=>129.70000000000002}, {"Cho'Gath"=>129.70000000000002}, {"Kassadin"=>122.5}, {"Taric"=>121.0}, {"Alistar"=>120.19}]how about using some of the indices we defined?... for instance, if we want to know which champions produce the greatest damage we could try sorting by our 'nuke_index', (notice that the assumptions on what make a good 'nuke' are subjective, but that's the fun of it; we can model our assumptions and see how the data changes in response.)
[3] pry(main)> ds.order(Sequel.desc(:nuke_index)).limit(5).collect{|c| {c.name => [c.total_damage, c.total_move_speed, c.total_mana, c.ability_power]}} => [{"Karthus"=>[100.7, 335.0, 1368.0, 10]}, {"Morgana"=>[114.58, 335.0, 1320.0, 9]}, {"Ryze"=>[106.0, 335.0, 1240.0, 10]}, {"Karma"=>[109.4, 335.0, 1320.0, 9]}, {"Lux"=>[109.4, 340.0, 1150.0, 10]}]
From my experience in the game, these champions are certainly heavy hitters. What do you think?
and (now I risk becoming addicted to DataHut myself), here's some further guesses with an 'easy_nuke' index (champions that have a lot of damage, but are also less difficult to play):
[4] pry(main)> ds.order(Sequel.desc(:easy_nuke_index)).limit(5).collect{|c| c.name} => ["Sona", "Ryze", "Nasus", "Soraka", "Heimerdinger"]makes sense, but is still fascinating... what about my crack at a support_index (champions that have a lot of regen, staying power, etc.)?
[5] pry(main)> ds.order(Sequel.desc(:support_index)).limit(5).collect{|c| c.name} => ["Sion", "Diana", "Nunu", "Nautilus", "Amumu"]
You get the idea now! Extract your data from anywhere, transform it however you like and analyze it for insights!
Have fun!
Metadata Object Store
DataHut also supports a basic Ruby object store for storing persistent metadata that might be useful during extract and transform passes.
Examples:
-
dh.extract(urls) do |r, url| ... # names => ["damage", "health", "mana", "move_speed", "armor", "spell_block", "health_regen", "mana_regen"] # DataHut also allows you to store metadata for the data warehouse during any processing phase for later retrieval. # Since we extract the data only once, but may need stats names for subsequent transforms, we can store the # stats names in the metadata for later use: dh.store_meta(:stats, names) ... end ... # later... we can fetch the metadata that was written during the extract phase and use it... stats = dh.fetch_meta(:stats) # stats => ["damage", "health", "mana", "move_speed", "armor", "spell_block", "health_regen", "mana_regen"]
Caveats: Because the datastore can support any Ruby object (including custom ones) it is up to the caller to make sure that custom classes are in context before storage and fetch. i.e. if you store a custom object and then fetch it in a context that doesn't have that class loaded, you'll get an error. For this reason it is safest to use standard Ruby types (e.g. Array, Hash, etc.) that will always be present.
See DataHut::DataWarehouse#store_meta and DataHut::DataWarehouse#fetch_meta for details.
TODOS
- further optimizations
- time-based series and binning helpers (by week/day/hour/5-min/etc).
Contributing
- Fork it
- Create your feature branch (
git checkout -b my-new-feature) - Commit your changes (
git commit -am 'Added some feature') - Push to the branch (
git push origin my-new-feature) - Create new Pull Request