RedAmber

![]()

Rubyistのためのデータフレームライブラリ.


概要
- RedAmberはRubyで書かれたデータフレームライブラリです。Apache Arrowの列指向データフォーマットを扱うことができます。
- Rubyらしいブロックやコレクションを使って、Rubyらしい書き方でデータフレームの操作ができることを目指しています。
- このリポジトリは開発コンテナ(Dev Container)をサポートしているので、RedAmberの操作が容易に試せます。
- 使用例が豊富なドキュメントと、127項目の主な操作例を記載したJupyter Notebookドキュメントがあります。
必要な環境
Ruby
- Ruby 3.0 以上.
ライブラリ
gem 'red-arrow', '>= 12.0.0' # お使いの環境に合わせた Apache Arrow が必要です
# 下記のインストールを参照してください
gem 'red-arrow-numo-narray' # 必要に応じて。Numo::NArray との連携またはランダムサンプリングが必要な場合。
gem 'red-parquet', '>= 12.0.0' # 必要に応じて。Parquet の入出力が必要な場合。
gem 'red-datasets-arrow' # 必要に応じて。Red Datasets を利用する場合。
gem 'red-arrow-activerecord' # 必要に応じて。Active Record とのデータ交換が必要な場合。
gem 'rover-df', # 必要に応じて。Rover::DataFrame に対する入出力が必要な場合。
インストール
RedAmberをインストールする前に、下記のライブラリのインストールが必要です。
- Apache Arrow (>= 12.0.0)
- Apache Arrow GLib (>= 12.0.0)
- Apache Parquet GLib (>= 12.0.0) # Parquetの入出力が必要な場合。
環境ごとの詳しいインストール方法は、 Apache Arrow install document を参照してください。
Ubuntuの場合の最低限必要なインストール例:
sudo apt update sudo apt install -y -V ca-certificates lsb-release wget wget https://apache.jfrog.io/artifactory/arrow/$(lsb_release --id --short | tr 'A-Z' 'a-z')/apache-arrow-apt-source-latest-$(lsb_release --codename --short).deb sudo apt install -y -V ./apache-arrow-apt-source-latest-$(lsb_release --codename --short).deb sudo apt update sudo apt install -y -V libarrow-dev libarrow-glib-devFedora 39 (Rawhide)の場合:
sudo dnf update sudo dnf -y install gcc-c++ libarrow-devel libarrow-glib-devel ruby-devel libyaml-develmacOS の場合は、Homebrewを使用する:
brew install apache-arrow apache-arrow-glib
Apache Arrowがインストールできたら、下記の行をGemfileに追加してください:
gem 'red-arrow', '>= 12.0.0'
gem 'red_amber'
gem 'red-arrow-numo-narray' # 必要に応じて。Numo::NArray との連携またはランダムサンプリングが必要な場合。
gem 'red-parquet', '>= 12.0.0' # 必要に応じて。Parquetの入出力が必要な場合。
gem 'red-datasets-arrow' # 必要に応じて。Red Datasets を利用する場合。
gem 'red-arrow-activerecord' # 必要に応じて。Active Record とのデータ交換が必要な場合。
gem 'rover-df', # 必要に応じて。Rover::DataFrameに対する入出力が必要な場合。
bundle installとするか、または gem install red_amberとしてインストールしてください。
Development Containersによる開発環境
このリポジトリは 開発コンテナ(Dev Container)をサポートしています。 これを使うと、ローカルの環境を変更することなく、RedAmberに必要なツール一式を含んだ環境を準備することができます。この環境には、Ruby、Apache Arrow、RedAmberのソースツリー、GitHub CI、サンプルデータセット、IRubyカーネルを含んだJupyter Labなどが含まれています。
RedAmber用のDev Containerは、.devcontainer ディレクトリに必要な設定が書かれています。
使用例は、開発コンテナ(Development Containers)の利用をご参照ください。
Docker イメージと Jupyter Notebook
(注:将来削除される可能性があります。上記のDev Containerをご活用ください。)
このリポジトリのdocker フォルダーから Docker コンテナ環境を生成できます。リポジトリをクローンしてから、dockerフォルダーにある readme を参照してください。その環境では docker/notebook フォルダーにある Jupyter Notebookイメージを試用できます。
このREADMEの内容をネットワーク上のJupyter Notebookでインタラクティブに試用することも出来ます。 Binder.
![]()
Jupyter Notebookの環境を含めた他の多くのデータ処理用のライブラリーとともにRedAmberもパッケージングされたDocker Imageとして、RubyData Docker Stacks が利用できます(Thanks to Kenta Murata).
他のデータフレームライブラリとの比較表
RedAmberの基本的な機能をPython pandas や R Tidyverse や Julia DataFrames と比較した表は DataFrame_Comparison_ja.md にあります(Thanks to Benson Muite).
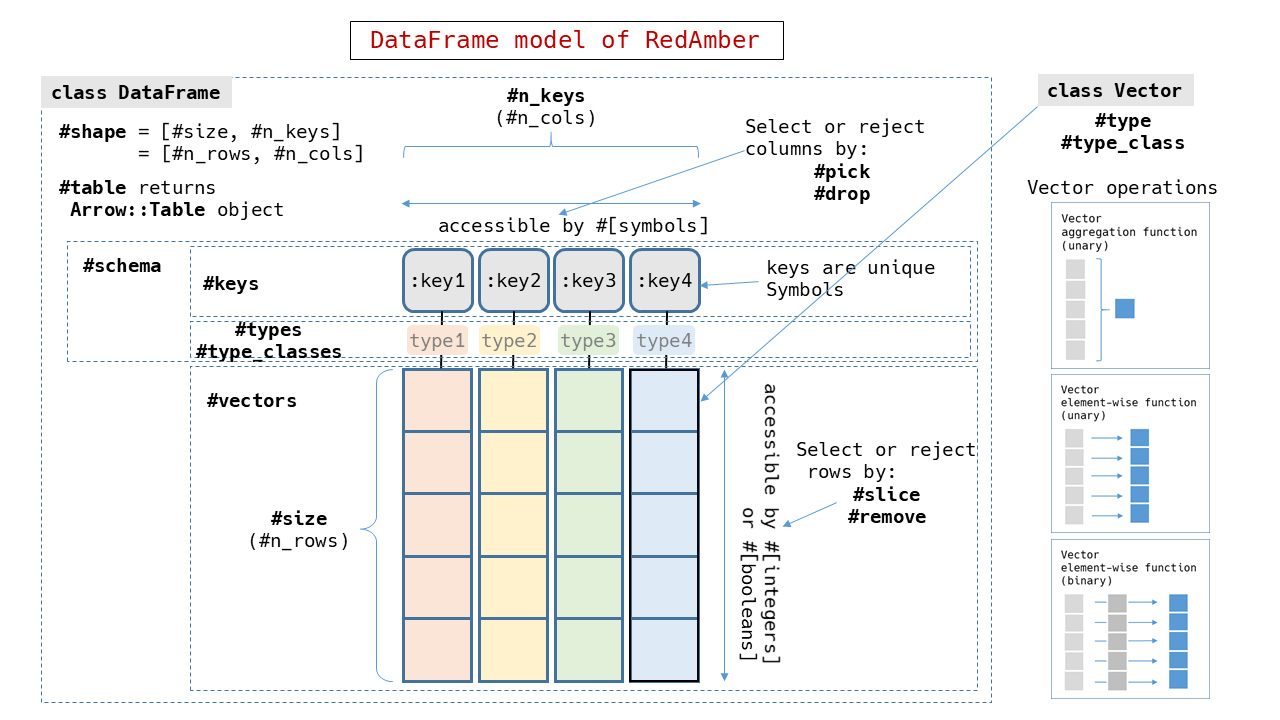
RedAmberのデータフレーム
クラス RedAmber::DataFrame は2次元のデータの集まりを表現します。
その実体は Red Arrowの Tableオブジェクトです。
それではライブラリをロードしていくつかの例を試してみましょう。
require 'red_amber' # require 'red-amber' でもOKです.
include RedAmber
例: diamonds データセット
もしまだであれば、Red DatasetsのArrow拡張を
gem install red-datasets-arrow
としてインストールしてから次を実行してください。
require 'datasets-arrow' # サンプルデータのロードのため
dataset = Datasets::Diamonds.new
diamonds = DataFrame.new(dataset) # v0.2.3以前では, `dataset.to_arrow`とする必要があります。
# =>
#<RedAmber::DataFrame : 53940 x 10 Vectors, 0x000000000000f668>
carat cut color clarity depth table price x ... z
<double> <string> <string> <string> <double> <double> <uint16> <double> ... <double>
0 0.23 Ideal E SI2 61.5 55.0 326 3.95 ... 2.43
1 0.21 Premium E SI1 59.8 61.0 326 3.89 ... 2.31
2 0.23 Good E VS1 56.9 65.0 327 4.05 ... 2.31
3 0.29 Premium I VS2 62.4 58.0 334 4.2 ... 2.63
4 0.31 Good J SI2 63.3 58.0 335 4.34 ... 2.75
: : : : : : : : : ... :
53937 0.7 Very Good D SI1 62.8 60.0 2757 5.66 ... 3.56
53938 0.86 Premium H SI2 61.0 58.0 2757 6.15 ... 3.74
53939 0.75 Ideal D SI2 62.2 55.0 2757 5.83 ... 3.64
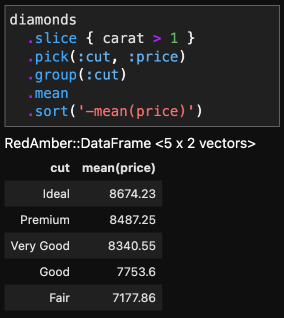
例えば、1カラット以下のレコードに対し、cut毎の平均のpriceを求めるには次のようにします。
df = diamonds
.slice { carat > 1 } # #sliceの代わりに#filterでも可
.group(:cut)
.mean(:price) # ここで:priceを指定する場合はgroupの前のpickは不要
.sort('-mean(price)')
# =>
#<RedAmber::DataFrame : 5 x 2 Vectors, 0x000000000000f67c>
cut mean(price)
<string> <double>
0 Ideal 8674.23
1 Premium 8487.25
2 Very Good 8340.55
3 Good 7753.6
4 Fair 7177.86
Arrowのデータはイミュータブルなので、これらのメソッドは新しいオブジェクトを返します。
次の例は、列をリネームしてから新しい列に簡単な計算の結果を格納します。
usdjpy = 110.0 # 今よりずっと円高の頃
df.rename('mean(price)': :mean_price_USD)
.assign(:mean_price_JPY) { mean_price_USD * usdjpy }
# =>
#<RedAmber::DataFrame : 5 x 3 Vectors, 0x000000000000f71c>
cut mean_price_USD mean_price_JPY
<string> <double> <double>
0 Ideal 8674.23 954164.93
1 Premium 8487.25 933597.34
2 Very Good 8340.55 917460.37
3 Good 7753.6 852896.11
4 Fair 7177.86 789564.12
例: starwars データセット
次の例は、CSVファイルをダウンロードしてstarwars データセットを読み込みます。その後簡単なデータのクリーニングを行います。
uri = URI('https://vincentarelbundock.github.io/Rdatasets/csv/dplyr/starwars.csv')
starwars = DataFrame.load(uri)
starwars
.drop(0) # 不要な列を取り除く
.remove { species == "NA" } # 不要な行を取り除く
.group(:species) { [count(:species), mean(:height, :mass)] }
.slice { count > 1 } # #filterでも可
# =>
#<RedAmber::DataFrame : 8 x 4 Vectors, 0x000000000000f848>
species count mean(height) mean(mass)
<string> <int64> <double> <double>
0 Human 35 176.65 82.78
1 Droid 6 131.2 69.75
2 Wookiee 2 231.0 124.0
3 Gungan 3 208.67 74.0
4 Zabrak 2 173.0 80.0
5 Twi'lek 2 179.0 55.0
6 Mirialan 2 168.0 53.1
7 Kaminoan 2 221.0 88.0
より詳しいデータフレームの使用例については、DataFrame.md をご参照ください。
1次元のデータを保持する Vector
クラスRedAmber::Vector はデータフレームの中の列方向に格納された1次元のデータ列を保持します.
より詳しい使用例については Vector.md をご参照ください。
Jupyter Notebook
このリポジトリでは Quarto を使って、操作例を載せたJupyter Notebookのソースはqmd形式で保存し、gitの管理下に置いています。Notebookの生成は開発コンテナを使うと便利です。詳しくは開発コンテナ(Development Containers)の利用を利用して下さい。
開発
Dev Containersを利用してコンテナ上に開発環境を作成する方法がお勧めです。開発コンテナ(Development Containers)の利用例を参考にしてください。
または、ローカル環境に必要なライブラリをインストールした上で、下記を実行するとテストが走ります。
git clone https://github.com/red-data-tools/red_amber.git
cd red_amber
bundle install
bundle exec rake test
RedAmberの開発では、rake test は必須ですが、rake rubocop をパスすることはコントリビュートの際に必須ではありません。このプロジェクトではコードの書き方の好みを尊重します。ただしマージの際に書き方を統一させていただくことがあります。
コミュニティ
このプロジェクトを支援して頂けると嬉しいです。支援の方法はいくつかあります。
- discussionsでお話ししましょう!
- Q and Aや使用方法、豆知識などを見流ことができます。
- 疑問に思っていることを質問できます。
- 新しいアイデアを共有する。アイデアはdiscussionからissueに昇格させて育てていくこともあります。漠然としたアイデアでもdiscussionから始めて大きくしていきましょう。
- バグ報告や新しい機能の提案
- バグの修正やプルリクエスト
- ドキュメントを修正したり、不明確なところを直したり、新しく追加しましょう。 皆さんのご参加をお待ちしています。
License
The gem is available as open source under the terms of the MIT License.