![]()
SSHKit is a toolkit for running commands in a structured way on one or more servers.


How might it work?
The typical use-case looks something like this:
require 'sshkit/dsl'
on %w{1.example.com 2.example.com}, in: :sequence, wait: 5 do
within "/opt/sites/example.com" do
as :deploy do
with rails_env: :production do
rake "assets:precompile"
runner "S3::Sync.notify"
execute "node", "socket_server.js"
end
end
end
end
One will notice that it's quite low level, but exposes a convenient API, the
as()/within()/with() are nestable in any order, repeatable, and stackable.
When used inside a block in this way, as() and within() will guard
the block they are given with a check.
In the case of within(), an error-raising check will be made that the directory
exists; for as() a simple call to sudo su -<user> whoami wrapped in a check for
success, raising an error if unsuccessful.
The directory check is implemented like this:
if test ! -d <directory>; then echo "Directory doesn't exist" 2>&1; false; fi
And the user switching test implemented like this:
if ! sudo su <user> -c whoami > /dev/null; then echo "Can't switch user" 2>&1; false; fi
According to the defaults, any command that exits with a status other than 0
raises an error (this can be changed). The body of the message is whatever was
written to stdout by the process. The 1>&2 redirects the standard output
of echo to the standard error channel, so that it's available as the body of
the raised error.
Helpers such as runner() and rake() which expand to execute(:rails, "runner", ...) and
execute(:rake, ...) are convenience helpers for Ruby, and Rails based apps.
Parallel
Notice on the on() call the in: :sequence option, the following will do
what you might expect:
on(in: :parallel) { ... }
on(in: :sequence, wait: 5) { ... }
on(in: :groups, limit: 2, wait: 5) { ... }
The default is to run in: :parallel which has no limit. If you have 400 servers,
this might be a problem and you might better look at changing that to run in
groups, or sequence.
Groups were designed in this case to relieve problems (mass Git checkouts) where you rely on a contested resource that you don't want to DDOS by hitting it too hard.
Sequential runs were intended to be used for rolling restarts, amongst other similar use-cases.
Synchronisation
The on() block is the unit of synchronisation, one on() block will wait
for all servers to complete before it returns.
For example:
all_servers = %w{one.example.com two.example.com three.example.com}
site_dir = '/opt/sites/example.com'
# Let's simulate a backup task, assuming that some servers take longer
# then others to complete
on all_servers do |host|
within site_dir do
execute :tar, '-czf', "backup-#{host.hostname}.tar.gz", 'current'
# Will run: "/usr/bin/env tar -czf backup-one.example.com.tar.gz current"
end
end
# Now we can do something with those backups, safe in the knowledge that
# they will all exist (all tar commands exited with a success status, or
# that we will have raised an exception if one of them failed.
on all_servers do |host|
in site_dir do
backup_filename = "backup-#{host.hostname}.tar.gz"
target_filename = "backups/#{Time.now.utc.iso8601}/#{host.hostname}.tar.gz"
puts capture(:s3cmd, 'put', backup_filename, target_filename)
end
end
The Command Map
It's often a problem that programmatic SSH sessions don't have the same environment variables as interactive sessions.
A problem often arises when calling out to executables expected to be on
the $PATH. Under conditions without dotfiles or other environmental
configuration, $PATH may not be set as expected, and thus executables are not found where expected.
To try and solve this there is the with() helper which takes a hash of variables and makes them
available to the environment.
with path: '/usr/local/bin/rbenv/shims:$PATH' do
execute :ruby, '--version'
end
Will execute:
( PATH=/usr/local/bin/rbenv/shims:$PATH /usr/bin/env ruby --version )
By contrast, the following won't modify the command at all:
with path: '/usr/local/bin/rbenv/shims:$PATH' do
execute 'ruby --version'
end
Will execute, without mapping the environmental variables, or querying the command map:
ruby --version
(This behaviour is sometimes considered confusing, but it has mostly to do with shell escaping: in the case of whitespace in your command, or newlines, we have no way of reliably composing a correct shell command from the input given.)
Often more preferable is to use the command map.
The command map is used by default when instantiating a Command object
The command map exists on the configuration object, and in principle is quite simple, it's a Hash structure with a default key factory block specified, for example:
puts SSHKit.config.command_map[:ruby]
# => /usr/bin/env ruby
To make clear the environment is being deferred to, the /usr/bin/env prefix is applied to all commands.
Although this is what happens anyway when one would simply attempt to execute ruby, making it
explicit hopefully leads people to explore the documentation.
One can override the hash map for individual commands:
SSHKit.config.command_map[:rake] = "/usr/local/rbenv/shims/rake"
puts SSHKit.config.command_map[:rake]
# => /usr/local/rbenv/shims/rake
Another opportunity is to add command prefixes:
SSHKit.config.command_map.prefix[:rake].push("bundle exec")
puts SSHKit.config.command_map[:rake]
# => bundle exec rake
SSHKit.config.command_map.prefix[:rake].unshift("/usr/local/rbenv/bin exec")
puts SSHKit.config.command_map[:rake]
# => /usr/local/rbenv/bin exec bundle exec rake
One can also override the command map completely, this may not be wise, but it would be possible, for example:
SSHKit.config.command_map = Hash.new do |hash, command|
hash[command] = "/usr/local/rbenv/shims/#{command}"
end
This would effectively make it impossible to call any commands which didn't provide an executable in that directory, but in some cases that might be desirable.
Note: All keys should be symbolised, as the Command object will symbolize it's first argument before attempting to find it in the command map.
Output Handling
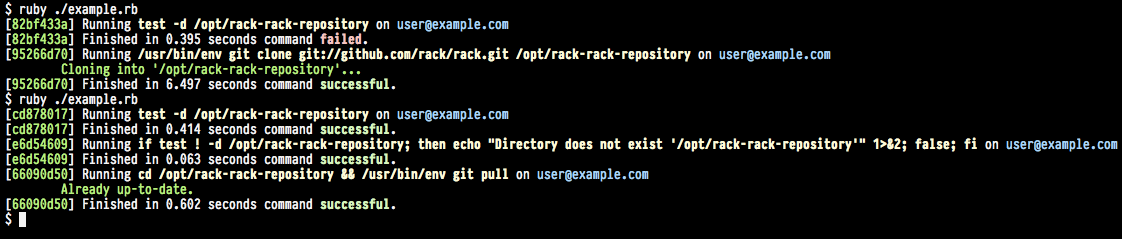
By default, the output format is set to :pretty:
SSHKit.config.format = :pretty
However, if you prefer minimal output, :dot format will simply output red or green dots based on the success or failure of operations.
To output directly to $stdout without any formatting, you can use:
SSHKit.config.output = $stdout
Output Verbosity
By default calls to capture() and test() are not logged, they are used
so frequently by backend tasks to check environmental settings that it
produces a large amount of noise. They are tagged with a verbosity option on
the Command instances of Logger::DEBUG. The default configuration for
output verbosity is available to override with SSHKit.config.output_verbosity=,
and defaults to Logger::INFO.
At present the Logger::WARN, ERROR and FATAL are not used.
Connection Pooling
SSHKit uses a simple connection pool (enabled by default) to reduce the
cost of negotiating a new SSH connection for every on() block. Depending on
usage and network conditions, this can add up to a significant time savings.
In one test, a basic cap deploy ran 15-20 seconds faster thanks to the
connection pooling added in recent versions of SSHKit.
To prevent connections from "going stale", an existing pooled connection will be replaced with a new connection if it hasn't been used for more than 30 seconds. This timeout can be changed as follows:
SSHKit::Backend::Netssh.pool.idle_timeout = 60 # seconds
If you suspect the connection pooling is causing problems, you can disable the pooling behaviour entirely by setting the idle_timeout to zero:
SSHKit::Backend::Netssh.pool.idle_timeout = 0 # disabled